
第5讲:数据可视化
数据可视化
导入:为什么要学习数据可视化
在前一讲中,我们已经讨论了数据分类、数据清洗和数据变换等内容。经过清洗与整理之后,数据已经从“原始、杂乱、不可直接分析”的状态,逐步转变为“结构化、规范化、可用于建模”的状态。但即便如此,如果我们不能把数据中的规律、差异和关系直观地表达出来,那么数据分析的价值仍然难以真正传递。
这就是数据可视化的重要性所在。所谓数据可视化,就是借助图形、颜色、位置、大小、形状等视觉编码方式,把抽象的数据转化为人们更容易感知、理解和解释的信息。与单纯的表格和数字相比,图形能够更快地揭示分布特征、变化趋势、变量关系和异常结构,因此是数据分析中不可替代的重要工具。
从数据科学的流程来看,数据可视化至少具有以下几方面作用:
- 帮助探索数据。在正式建模之前,通过可视化可以快速了解数据分布、变量关系、是否存在异常值以及是否有明显偏态。
- 帮助发现规律。很多统计关系并不是先通过公式发现的,而是先通过图形观察到趋势,再进一步进行建模和检验。
- 帮助验证分析结果。模型得到结论后,往往还需要借助图形进行解释和检验,例如残差图、拟合图、分类结果图等。
- 帮助沟通与表达。数据分析不仅是技术过程,也是结果传达过程。图形比公式和表格更容易让非专业受众理解研究发现。
- 帮助辅助决策。无论是在商业分析、媒体传播、公共管理还是科研写作中,可视化都是将数据转化为决策依据的重要桥梁。
因此,可以说:数据可视化不仅是“把数据画出来”,更是把数据背后的结构、规律与结论表达出来。
DEMO
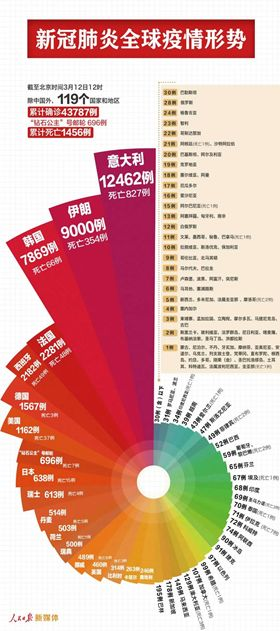
- 南丁格尔玫瑰图是经典的数据可视化案例之一。它不仅展示了数据大小,还通过角度与面积的变化强化了比较效果,说明图形不仅具有展示功能,也具有解释与传播功能。
图形初阶
一个例子
- 病人 A 和 B 对两种药物五个剂量水平上的响应情况。
dose <- c(20, 30, 40, 45, 60)
drugA <- c(16, 20, 27, 40, 60)
drugB <- c(15, 18, 25, 31, 40)
plot(dose, drugA, type="b")
```{r, fig.width=8} dose <- c(20, 30, 40, 45, 60) drugA <- c(16, 20, 27, 40, 60) drugB <- c(15, 18, 25, 31, 40) plot(dose, drugA, type=”b”)
* 这个例子说明:当我们想展示“剂量变化是否会带来药物响应变化”时,图形往往比简单的数值表更容易帮助我们观察趋势。图形的首要作用,就是帮助我们快速建立对数据整体结构的直观认识。
## 图形参数
```{r,fig.width=4.5, fig.height=3}
opar <- par(no.readonly=TRUE)
par(lty=2, pch=17)#线条类型和点符号
plot(dose, drugA, type="b")
par(opar)
图形属性
- 颜色参数:
col,col.axis,col.lab,col.main,col.sub,fg,bg - 文本属性:
cex,cex.axis,cex.main - 字体属性:
font,font.axis,font.lab,font.main - 例如:
par(font.lab=3, cex.lab=1.5, font.main=4, cex.main=2) - 图形尺寸:
pin:以英寸表示的图形尺寸(宽和高)mai:以数值向量表示的边界大小,顺序为“下、左、上、右”,单位为英寸mar:以数值向量表示的边界大小,顺序为“下、左、上、右”,默认值为c(5, 4, 4, 2) + 0.1
- 这部分说明,一个图形是否“好看”只是次要的,更重要的是图形是否清晰、是否便于比较、是否能够准确传递信息。图形参数的设置,本质上是在优化图形的可读性。
添加文本、自定义坐标轴和图例
plot(dose, drugA, type="b", col="red", lty=2, pch=2, lwd=2,
main="Clinical Trials for Drug A",sub="This is hypothetical data",
xlab="Dosage", ylab="Drug Response",xlim=c(0, 60), ylim=c(0, 70))
添加文本、自定义坐标轴和图例
- 标题:
title() - 坐标轴:
axis() - 参考线:
abline() - 图例:
legend() - 文本标注:
text() - 数学标注:
plotmath()或demo(plotmath)
图形组合
- 函数:
par(),par(mfrow=c(2,2))
attach(mtcars)
opar <- par(no.readonly=TRUE)
par(mfrow=c(2,2))
plot(wt, mpg, main="Scatterplot of wt vs. mpg")
plot(wt, disp, main="Scatterplot of wt vs. disp")
hist(wt, main="Histogram of wt")
boxplot(wt, main="Boxplot of wt")
- 图形组合的作用是把多个视角放在同一页面中共同观察。这样可以同时看分布、关系与异常,有利于形成对数据更完整的理解。
数据可视化的重要性
可视化在数据科学中的角色
如果把数据科学看作一个完整流程,那么可视化几乎贯穿始终:
- 在数据获取后,可视化帮助我们快速认识数据结构;
- 在数据清洗时,可视化帮助识别异常值、缺失模式和分布偏态;
- 在建模之前,可视化帮助判断变量关系、发现潜在假设;
- 在建模之后,可视化帮助展示结果、验证模型和解释结论;
- 在结果传播中,可视化帮助把复杂分析转化为直观表达。
从这个意义上说,数据可视化不是分析的附属环节,而是数据分析的核心组成部分。
为什么图形比表格更有力量
表格适合精确查阅数值,但不擅长揭示整体模式;图形虽然不一定能体现每一个精确数值,却特别擅长揭示结构与趋势。比如:
- 一组收入数据放在表格里,我们很难一眼看出其分布形态;
- 但画成直方图后,就可以迅速判断其是否偏态、是否多峰;
- 两个变量的几十组观测值放在表格里,很难看出关系;
- 但画成散点图后,线性关系、非线性关系、聚类结构和异常点往往立刻显现。
因此,图形的优势并不在于取代表格,而在于帮助我们更高效地理解表格中隐藏的信息。
一个好的可视化应当满足什么要求
一个有效的数据可视化,通常至少应当满足以下要求:
- 准确:图形必须忠实于数据,不能误导读者。
- 清晰:图形元素要简洁,重点突出,便于识别。
- 匹配问题:不同分析目的要选择不同图形,不能“为画图而画图”。
- 便于比较:优秀图形应能帮助读者快速完成组间比较、时间比较或结构比较。
- 服务表达:图形不仅要展示,还要支持解释和结论传达。
因此,学习数据可视化并不仅仅是学习函数怎么调用,更重要的是学会“面对一种数据和一种问题时,应该选择什么图,为什么这么画”。
常见图形汇总
按分析目的分类
从分析目的出发,常见的数据可视化图形大致可以分为以下几类:
- 展示分类数据分布:条形图、饼图、扇形图
- 展示连续变量分布:直方图、核密度图、箱线图、小提琴图
- 展示两个变量关系:散点图、气泡图、折线图
- 展示多个变量关系:散点图矩阵、热力图、平行坐标图
- 展示时间变化趋势:折线图、面积图
- 展示组成结构:堆积条形图、饼图、环形图、树图
- 展示空间分布:地图、热区图、地理气泡图
- 展示高维数据模式:降维散点图、聚类热图、网络图
这个分类方式非常重要。因为图形的选择,不应该只看“我会不会画”,而应该先问“我想展示什么”。
按数据类型分类
从数据类型角度,也可以大致归纳为:
- 分类变量:条形图、饼图、马赛克图
- 连续变量:直方图、密度图、箱线图
- 时间序列数据:折线图、面积图
- 二维连续变量关系:散点图、二维密度图
- 多变量数据:散点图矩阵、热力图、雷达图
基本图形
条形图
- 条形图通过垂直或水平条形展示类别型变量的分布(频数或频率)。
barplot()的最简单用法是:barplot(height)- 条形图特别适合比较不同类别的大小差异,因此在调查数据、媒体数据和分类统计中非常常见。
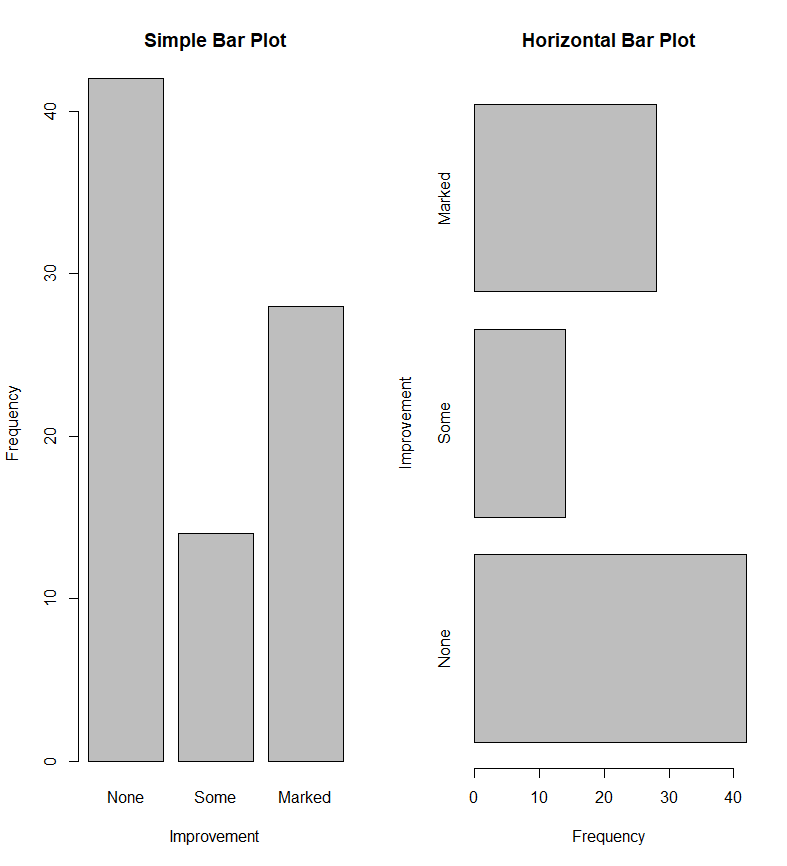
条形图的适用场景
- 比较不同专业学生人数
- 比较不同平台用户规模
- 比较不同地区样本量
展示问卷选项的频数分布
- 当重点在“类别之间谁多谁少”时,条形图通常是最优先考虑的图形之一。
箱线图
- 箱线图(又称盒须图)通过绘制连续型变量的五数总括,即最小值、下四分位数、中位数、上四分位数以及最大值,描述连续型变量的分布。
- 箱线图能够显示出可能的离群点,即超出
±1.5×IQR范围之外的观测值。 - 箱线图特别适合比较不同组之间的中位数、离散程度和异常值情况。
箱线图
boxplot(mpg ~ cyl, data=mtcars, main="Car Mileage Data",
xlab="Number of Cylinders", ylab="Miles Per Gallon")
箱线图的适用场景
- 比较不同班级考试成绩分布
- 比较不同平台停留时长分布
- 比较不同地区收入水平分布
- 识别极端值和异常观测
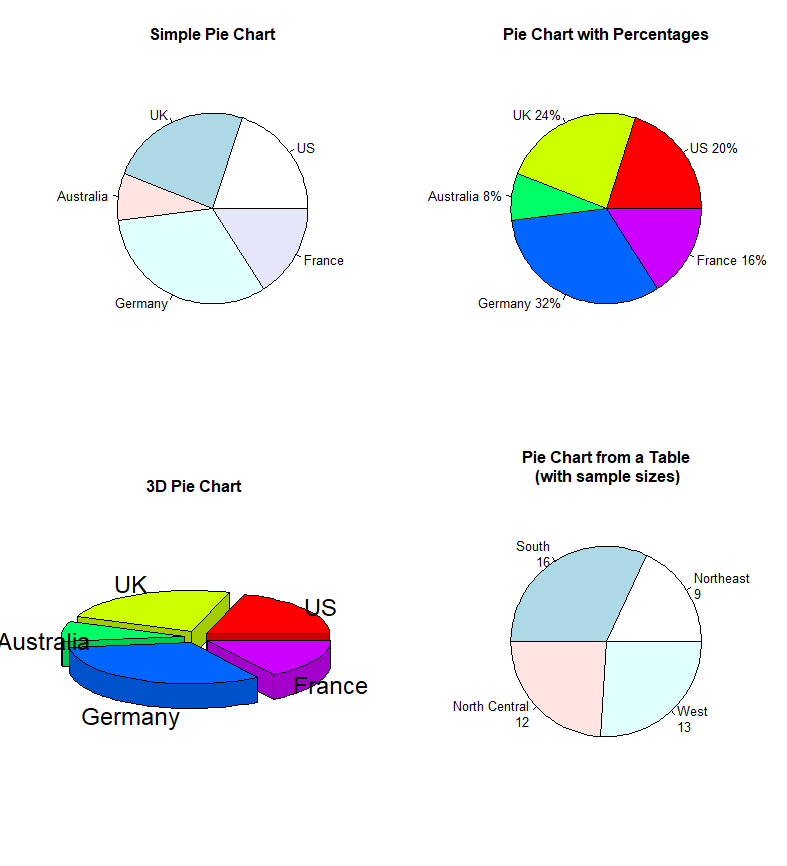
饼图
- 饼图表示同一变量不同水平所占的比例:
pie(x, labels)。 - 其中
x是非负数值向量,表示各扇形面积;labels是各扇形标签。 - 饼图的优点是结构直观,适合展示组成;缺点是当类别过多时不利于精确比较。
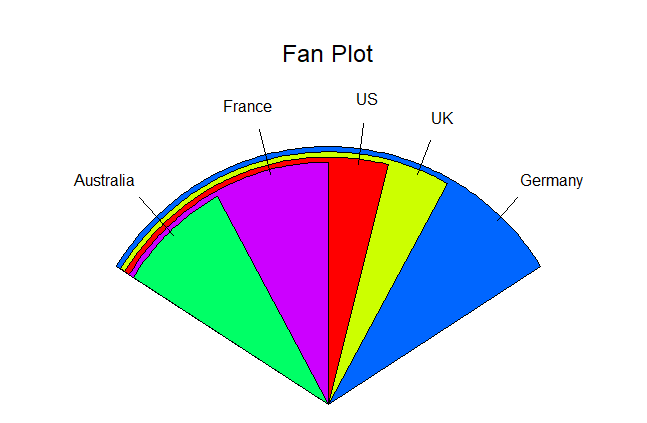
扇形图
- 扇形图是通过
plotrix包中的fan.plot()函数实现的。 - 相比普通饼图,扇形图有时能提供更有层次感的视觉效果,但本质上仍然是结构占比图。
直方图
- 直方图用于展示连续型变量的分布情况:
hist(x)。 - 它特别适合观察变量的集中程度、离散程度、偏态特征以及是否存在多个峰值。
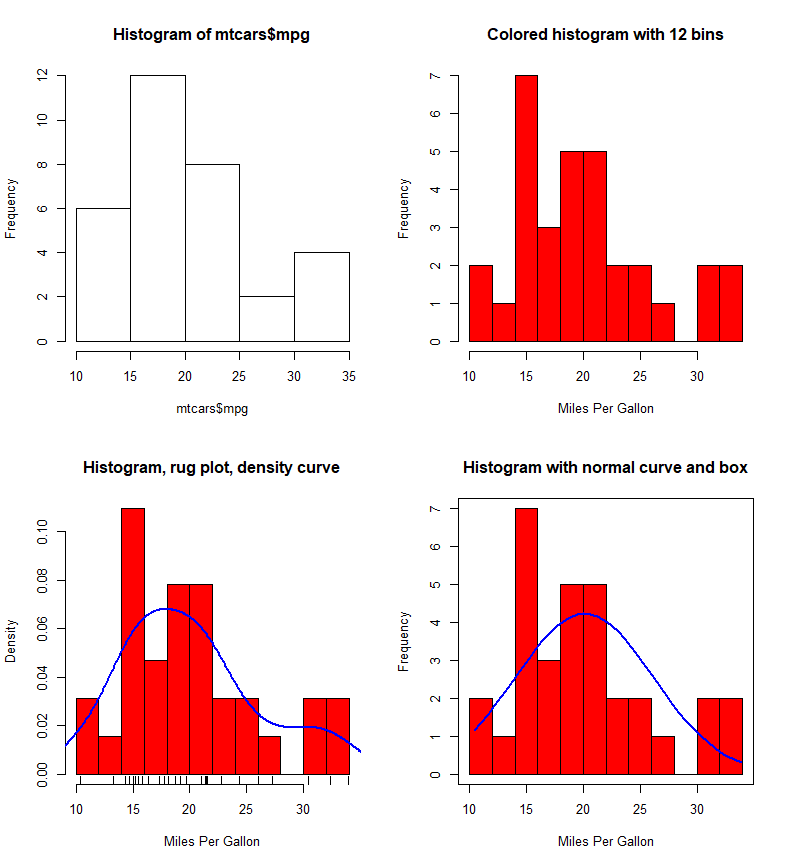
核密度图
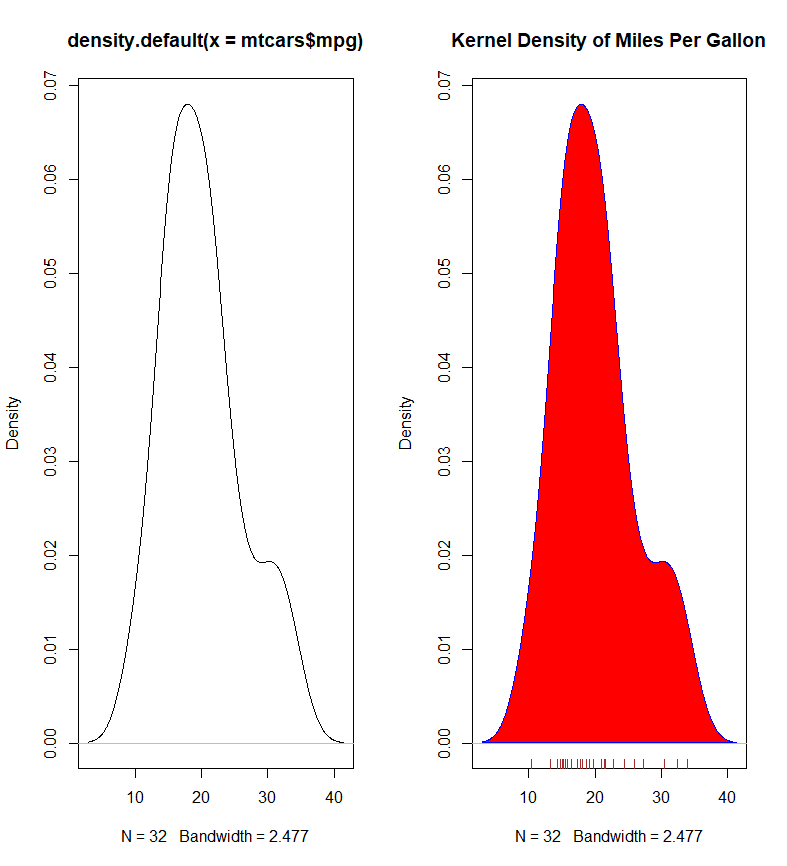
- 核密度图是一种观察连续型变量分布的有效方法,绘制方法为:
plot(density(x))。 - 与直方图相比,密度图更平滑,更适合观察分布轮廓。
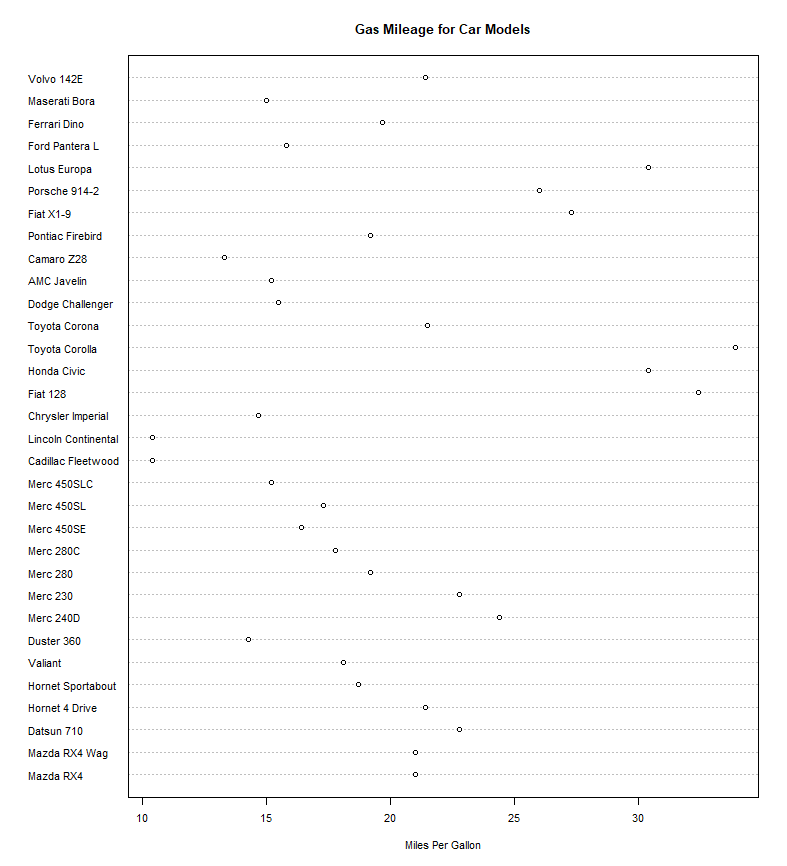
点图
- 点图提供了一种在简单水平刻度上绘制大量有标签值的方法:
dotchart(x, labels=)。 x是数值向量,labels是每个点对应的标签。- 当类别较多但又希望保留标签时,点图往往比条形图更紧凑。
散点图
- 散点图用于描述两个连续型变量之间的关系。
- 它可以帮助我们观察线性关系、非线性关系、聚类趋势和异常点。
- 在探索性分析中,散点图是最常用的图形之一。

散点图矩阵
- 散点图矩阵用于描述多个变量中任意两个连续型变量之间的关系。
- 它特别适合多变量探索性分析,可以快速了解多个变量之间是否存在相关结构。
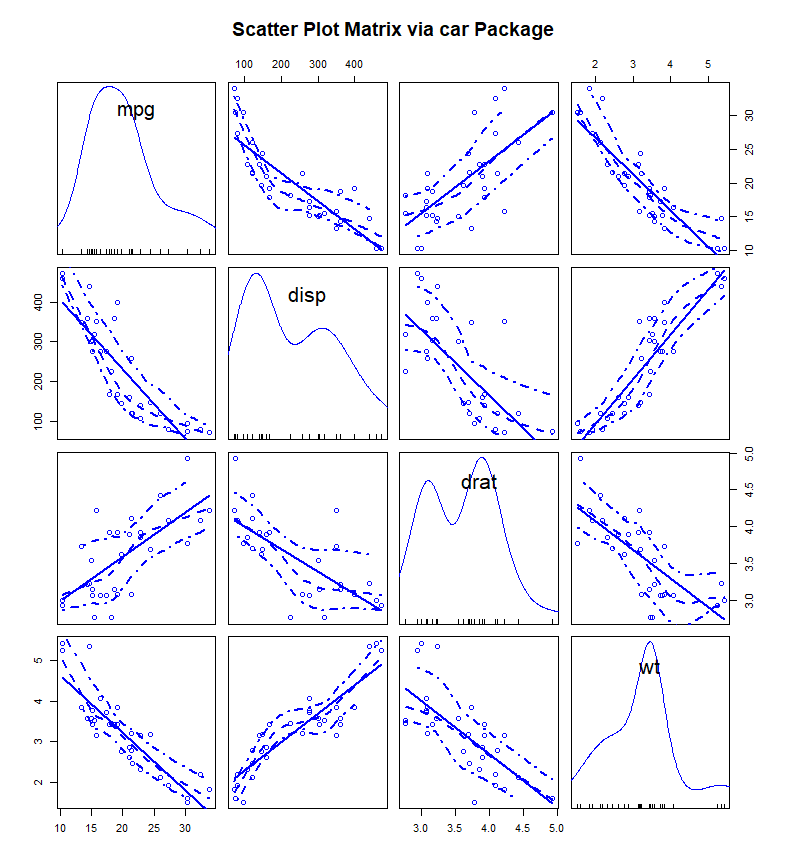
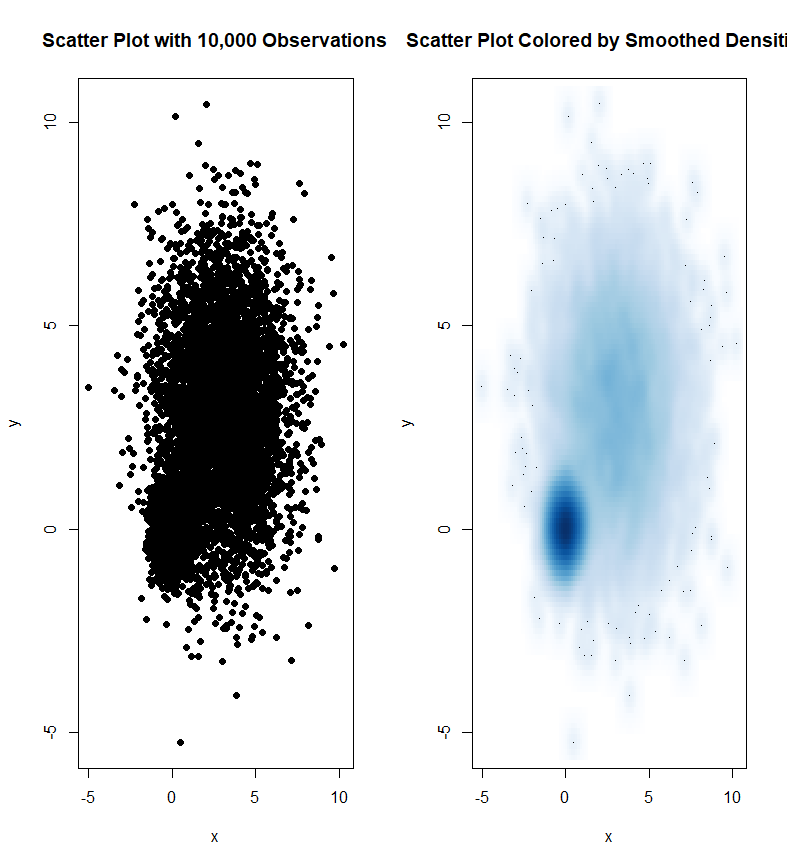
高密度散点图
- 当样本量非常大时,普通散点图可能出现点重叠问题,此时可以使用高密度散点图或二维密度图来改善可读性。
折线图
- 折线图最适合展示随时间变化的趋势,是时间序列数据分析中的基础图形。
- 当横轴具有顺序含义,例如年份、月份、日期或剂量水平时,折线图比条形图更能体现变化过程。
面积图与堆积图
- 面积图常用于展示总量随时间的变化;
- 堆积面积图和堆积条形图则适合同时展示总量变化与内部结构变化。
- 这类图形在媒体传播数据、平台运营数据和社会调查数据中非常常见。
热力图
- 热力图通过颜色深浅来表现矩阵或二维表中数值的大小。
- 它适合展示相关系数矩阵、词频矩阵、区域强度以及聚类结果。
- 当变量较多时,热力图比大规模表格更易于识别总体模式。
雷达图
- 雷达图适合展示一个对象在多个维度上的表现,如综合能力评价、品牌形象比较等。
- 但由于面积和角度容易造成视觉误差,因此在正式分析中应谨慎使用,更适合做概括性展示。
地图可视化
- 当数据具有空间属性时,可以通过地图进行可视化。
- 常见形式包括分级设色地图、点密度地图、气泡地图和热区图。
- 地图非常适合展示地区差异、空间分布和地理聚集现象。
常见图形与应用场景汇总
图形—数据类型—分析任务对应表
| 图形类型 | 主要数据类型 | 主要用途 |
|---|---|---|
| 条形图 | 分类变量 | 比较不同类别的频数、频率或均值 |
| 饼图/扇形图 | 分类变量 | 展示组成比例 |
| 直方图 | 连续变量 | 观察分布形态 |
| 核密度图 | 连续变量 | 平滑展示分布轮廓 |
| 箱线图 | 连续变量/分组变量 | 比较分布、识别异常值 |
| 点图 | 分类+数值 | 紧凑展示多类别数值 |
| 散点图 | 两个连续变量 | 观察相关关系与异常点 |
| 散点图矩阵 | 多个连续变量 | 多变量探索性分析 |
| 折线图 | 时间序列 | 展示趋势变化 |
| 面积图 | 时间序列/结构数据 | 展示趋势与组成 |
| 热力图 | 矩阵数据/多变量数据 | 展示强弱关系和整体模式 |
| 地图 | 空间数据 | 展示地理分布 |
图形选择的一般原则
在实际分析中,可以遵循一个简单原则:
- 想看分类比较,优先考虑条形图;
- 想看分布形态,优先考虑直方图、密度图、箱线图;
- 想看变量关系,优先考虑散点图;
- 想看时间变化,优先考虑折线图;
- 想看空间差异,优先考虑地图;
- 想看多变量整体模式,优先考虑热力图、散点图矩阵。
也就是说,图形选择的关键不在于“哪种图更漂亮”,而在于“哪种图更适合当前问题”。
ggplot2
ggplot2 包含以下几个概念
- 数据(Data)和映射(Mapping)
- 标度(Scale)
- 几何对象(Geometric)
- 统计变换(Statistics)
- 坐标系统(Coordinate)
- 图层(Layer)
- 分面(Facet)
ggplot2
- 数据(Data)和映射(Mapping):回答“使用什么数据,以及变量映射到哪些视觉元素上”。
- 标度(Scale):控制映射后图形属性的显示方式,例如坐标刻度和图例。
- 几何对象(Geometric):指图中实际看到的几何元素,如点、线、柱、面等。
- 统计变换(Statistics):对原始数据进行统计计算,例如回归线、置信区间、计数等。
- 分面(Facet):把数据按某种方式分组后分别绘图,适合做条件比较。
为什么要学习 ggplot2
与基础绘图系统相比,ggplot2 更强调“图形语法”。也就是说,图不再只是靠一个函数一次性画出来,而是把图形分解成数据、映射、图层、几何对象和标度等多个部分,再逐步组合。这种方式非常适合复杂可视化任务,也更符合现代数据分析的工作习惯。
ggplot2 图书推荐

实际应用中的可视化提醒
做图时应避免的问题
- 图形元素过多,导致读者抓不住重点;
- 颜色过于复杂,反而削弱比较效果;
- 纵轴截断不合理,造成视觉误导;
- 图形类型与数据不匹配;
- 把装饰性置于信息表达之前。
可视化不是装饰,而是分析
在很多初学者看来,数据可视化似乎只是报告最后的“美化步骤”。但实际上,真正好的可视化并不是装饰,而是分析过程本身。一个图形如果不能帮助发现问题、解释问题或支持结论,那么即使再精美,也不算高质量的数据可视化。
实际操作&小结
本讲围绕数据可视化展开,从图形初阶入手,介绍了图形参数、文本与图例添加、图形组合以及多种基础图形的应用,并进一步讨论了数据可视化在数据科学中的重要作用。
如果用一句话概括本讲内容,可以表述为:
数据可视化的本质,不只是把数据画出来,而是借助视觉表达把数据中的分布、关系、趋势和结构清晰地呈现出来。